Week 1 Introduction to Digital Practice
There was no workshop this week, but we had a meeting earlier where everyone gathered. I really felt that all the teachers were very nice! I'm already looking forward to the learning content of this academic year!
Week 2 Creating Websites
This week was the first workshop of the semester. I learned to use the browser's Inspect tool to view page source, logged in to my cPanel site, and uploaded a website I made to the host. Before class I had already studied HTML basics on Codecademy about page structure and elements like headings, paragraphs, links, and images, so it felt rewarding to connect those concepts to real site operations.
I also began using CSS to control fonts, sizes, and layout. Changing styles with CSS is far more flexible and interesting than tweaking elements one by one in an editor.
Thinking back, I remembered learning web design in junior high with Microsoft FrontPage. That approach was easy for beginners but lacked the flexibility of modern HTML/CSS. My current challenge is not writing individual elements, but designing an overall layout: hierarchy, spacing, and visual flow need improvement. I plan to focus on layout techniques like Flexbox, Grid, and wireframing to make my pages cleaner and more attractive.
We also tried to set up a site with FileZilla but could not connect due to technical issues. This reminded me to prepare better for workshops: install and test required software in advance, read the assigned materials, and check common connection settings (account, host, port, passive/active transfer) when problems arise.

Week 3 Web Scraping
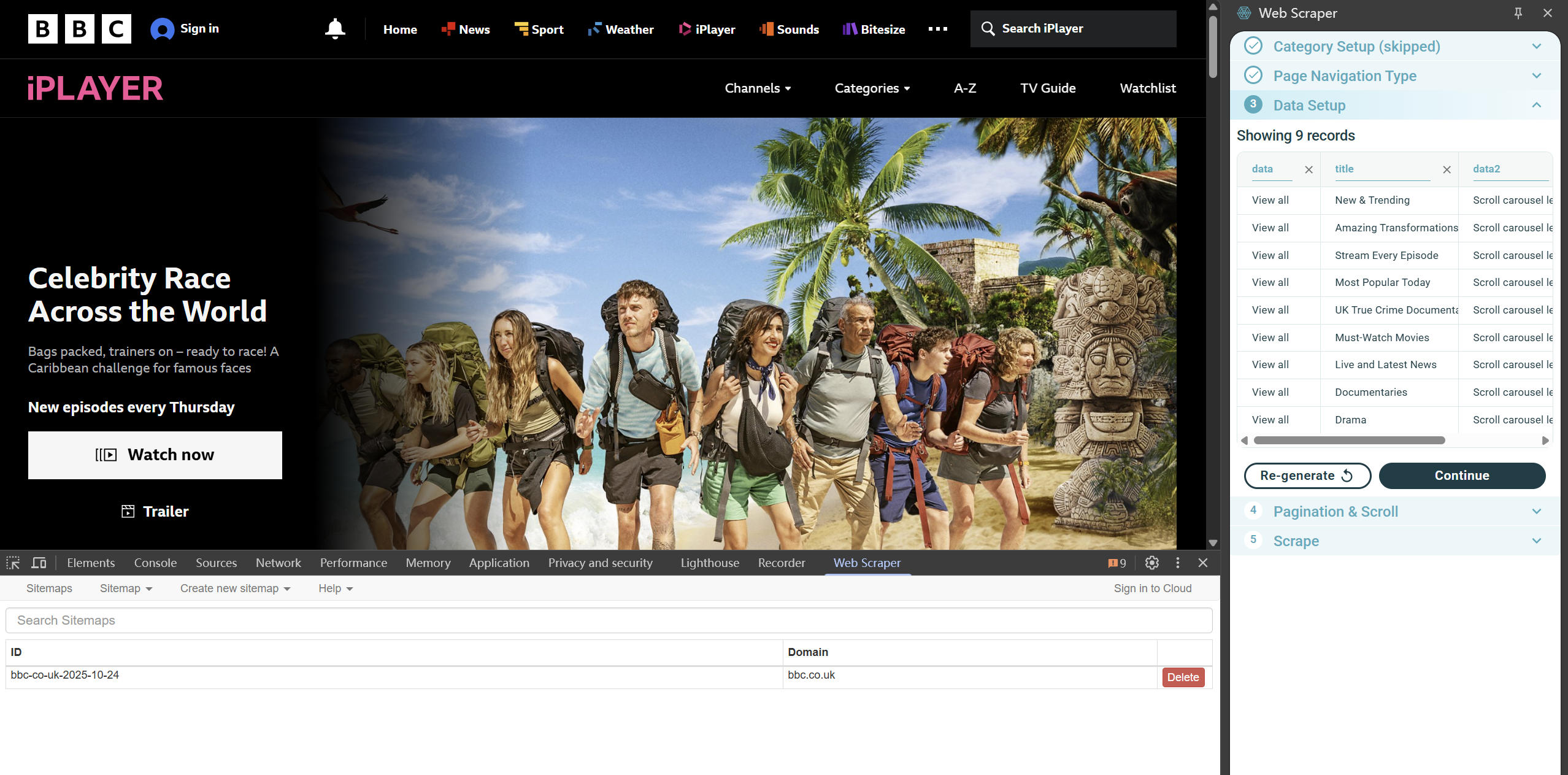
This week's workshop covered web scraping: using plugins or tools to extract webpage content and save it as structured tables. I practiced on a BBC iPlayer page with the WebScraper.io plugin, creating a sitemap and adding selectors to define the areas and data formats to scrape. After configuring selectors and navigation, data can be exported as CSV or Excel.
Web scraping is a practical skill: it speeds up market research, academic work, and competitor monitoring by collecting large amounts of structured data automatically. It can also help my job search by gathering job postings or company contacts from recruitment sites.
One class is only an introduction. My classmates and I ran into challenges like writing precise selectors, handling pagination and dynamic content, and cleaning scraped data. There are also legal and ethical considerations—avoid scraping sensitive or copyrighted material in bulk and respect site rules.
Next steps: practice scraping sites with different structures, deepen my knowledge of selectors, and learn tools for more advanced scraping.
Week 4 Data & Data Analysis
This week we focused on questionnaire design. Our group's topic is student engagement with AI in higher education. Following the instructor's advice, we narrowed the target population from university students to master's students to make the study more focused. The survey covers discipline (STEM, business, social sciences, medicine, etc.), AI use cases and motivations, frequency of use, and views on AI-related academic integrity issues.
Designing a logical, analyzable questionnaire is challenging. You must consider respondents' language, clarity and neutrality of questions, each item's relevance to the study goals, and whether answers will produce comparable variables for analysis (consistent scales, non-ambiguous options). We also discussed question order, filter questions, and response formats (single choice, multiple choice, Likert scales).
Overall, these three weeks formed a clear learning chain: 1.technical operation 2.data acquisition 3.data collection design. Weekly practice has been valuable, but I still need more hands-on experience and theoretical study to consolidate these skills.
Week 5 Data Visualisation
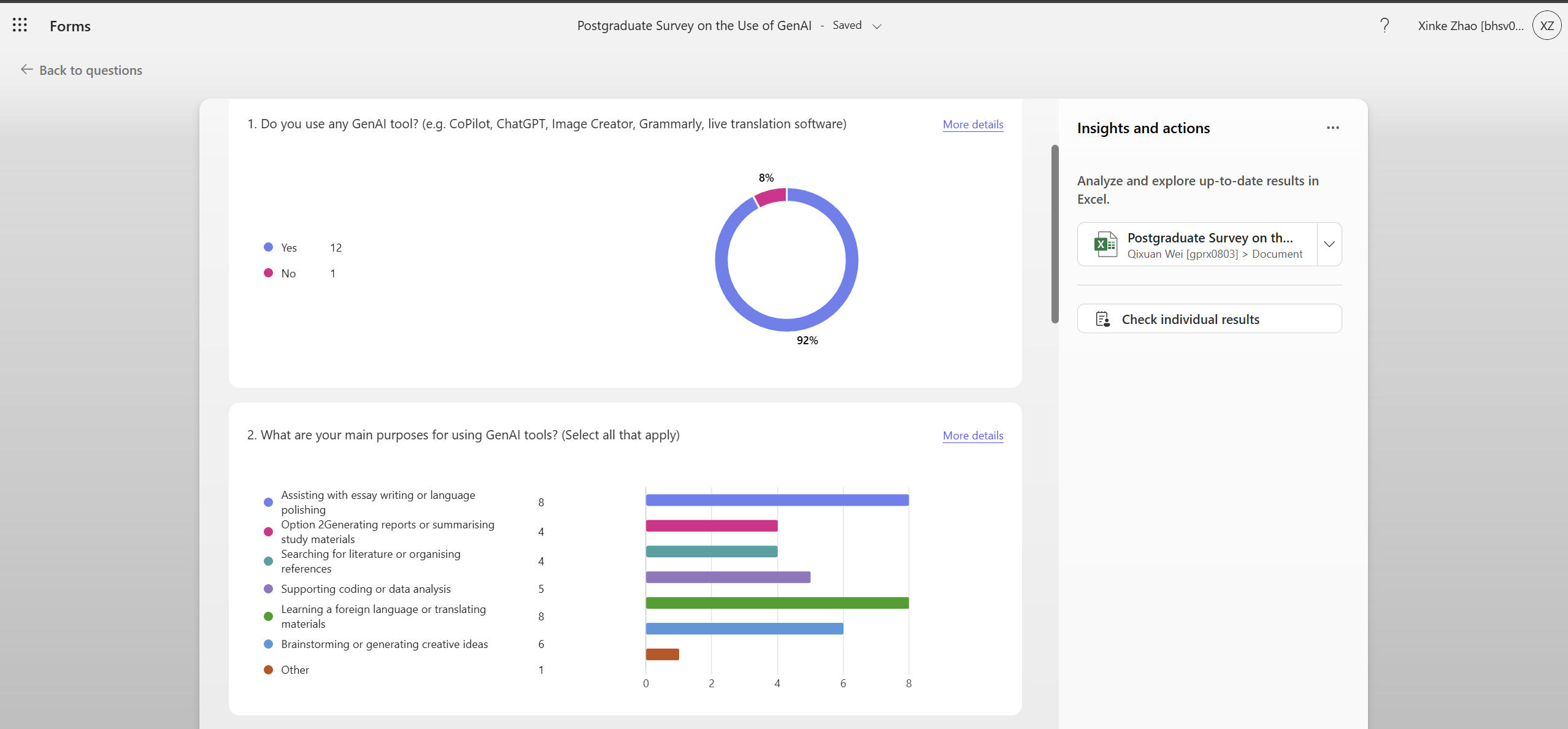
This week, our main task was to analyze and visualize the data collected from the questionnaire our group designed and published last week. A single data point on its own doesn't reveal much, but when combined with the right tools and analytical methods, it can show meaningful patterns and insights. In high school and university, I had some experience using Excel to create statistical charts such as bar charts, column charts, and pie charts, as well as using SPSS for basic data analysis - calculating maximum, minimum, mean, variance, and even running simple regression analyses.
Regarding our questionnaire, I found that the biggest problem our group faced was the small sample size. Another issue was the lack of diversity in our question design. For example, when asking about students' willingness to use AI, we could have allowed respondents to rank their priorities rather than just selecting multiple options. That would have made the data more analyzable and helped us avoid ending up with unfocused, hard-to-interpret multiple-choice results.
In this week's workshop, the instructor introduced us to a data visualization tool called Tableau. At first glance, I noticed that it shares some similarities with SPSS. After logging in and uploading our dataset, I found one of Tableau's advantages is its ability to automatically assign consistent colors to the same data categories, making visual comparison much clearer. However, since our dataset was relatively small and lacked strong correlations, there wasn't much for us to visualize meaningfully. This made me realize that we need to put more effort into the questionnaire design stage next time to ensure that our data is both diverse and analyzable.
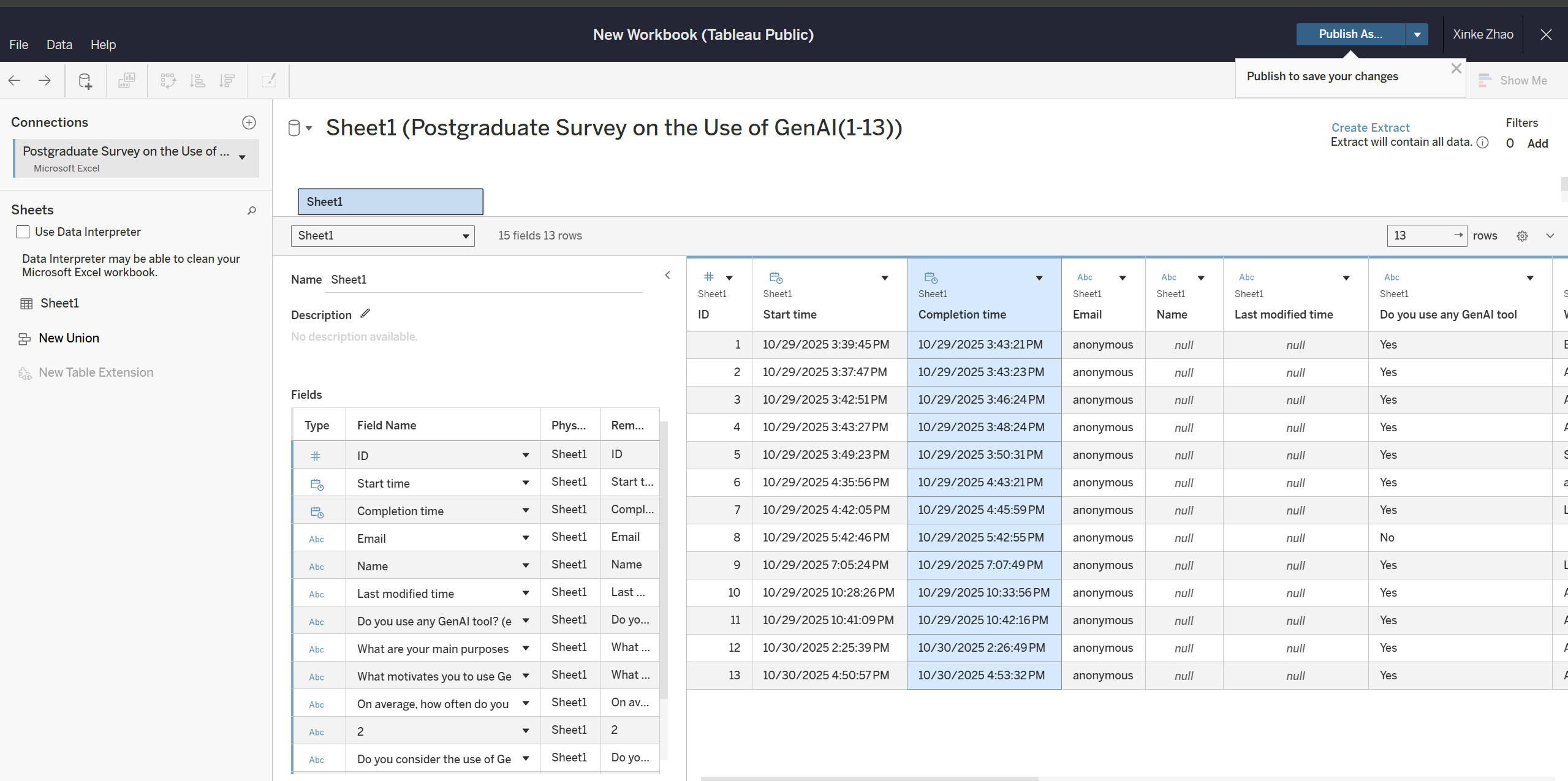
Week 6 Identity, Algorithmic Identity, and Data
This week's workshop focused on the data we share on the internet and how this information contributes to what is called an Algorithmic Identity. The lecturer divided personal data into six categories: content we share (images, audio, video), demographics, location data, search queries, browsing profiles (cookies and trackers), and biometric data. It may seem like we are simply posting photos or short updates on social media, but in fact time stamps, location tags, friend networks, likes and shares are also collected and used to build a digital profile of “who we are,” often without our awareness.
During class, I opened Facebook and Instagram and noticed personalised settings such as targeted advertisements that were different from other people's accounts. This made me realise that our online identity is not only what we choose to present, but also something continuously constructed and inferred from our data. Algorithmic Identity is not defined by ourselves but automatically generated by platforms based on our behaviour, search habits, and browsing preferences.
We also discussed biometric data, such as fingerprints and facial recognition. On the surface, we agree to provide this information, but sometimes facial data is generated automatically through photos or public surveillance and then used to track movement or behaviour patterns. In other words, our identity is not static; it is constantly recorded and processed within digital systems. The way platforms see, store, ignore, or filter information reflects the intentions and power structures behind different companies or institutions.
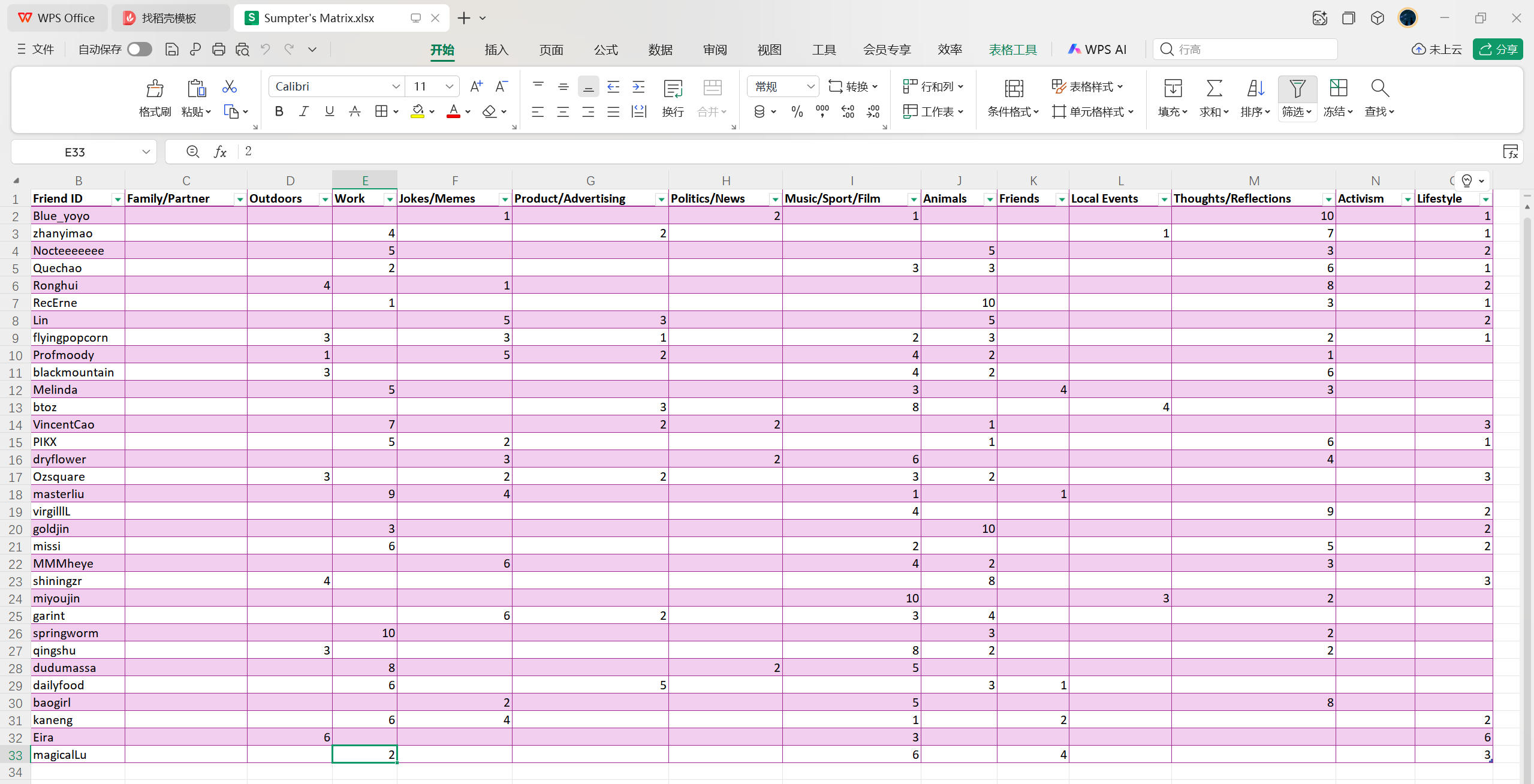
After this discussion, everyone in class selected 32 friends from their own social media and categorised their most recent 15 posts. There were 13 categories in total: family or partner, outdoors, work, jokes or memes, product or advertising, politics or news, music or sport, animals, friends, local events, thoughts or reflections, activism, and lifestyle. Although we encountered difficulties during categorisation—for example, a selfie in the park with a pet dog and friends could belong to several categories—I noticed clear preferences. One friend constantly shares their thoughts about movies, another posts mostly about workplace problems, and so on. In my mind, they are labelled as “movie lover,” “workaholic,” etc.
These identities can even predict our interests, consumption habits, or political views, and further influence what content or advertisements we encounter. Therefore, there is a clear gap between algorithmic identity and our real self. Platform algorithms may reinforce or reshape labels based on commercial goals, gradually influencing how we present ourselves and how we understand who we are.
Week 7 AI and Identities
This week's workshop focused on AI and identities, and we mainly practiced a prompting technique called negative prompting when interacting with ChatGPT. Following the instructor's guidance, I started a brand-new conversation with ChatGPT and explained that I wanted to write a story about helping a friend, who was a student director, negotiate with a swimming-pool manager and eventually persuade him to let us use the pool as our filming location. The initial result looked coherent, but after reading it again, I realized many details did not match real-life situations, for example, the negotiation taking place in an overly dramatic setting or the manager reacting strangely emotional. So, according to the task, I pointed out these unreasonable parts one by one and asked the AI to revise them. Surprisingly, after rounds of rejection and regeneration, the story gradually became more realistic and closer to my actual experience.
Throughout this process, I realized that AI is essentially drawing from existing datasets to produce the most statistically likely expression, even though such expressions may not feel truly authentic. When I emphasized or rejected specific details, the AI had to adjust its direction. In other words, interacting with AI is not about passively accepting the output, but about actively intervening, correcting, and even challenging it. This experience made me rethink the relationship between humans and AI: we are not passive receivers of knowledge, and we need to keep our agency. Otherwise, we may be misled by an apparently “reasonable narrative” generated by AI, and overlook the importance of our own lived experience.
The process of negative prompting also involved different emotions. At first, I felt slightly impatient and thought the revisions were troublesome. But as the story got closer and closer to reality, I suddenly realized that this repeated process of “negation” and regeneration was actually helping me revisit and rethink my own experience. Especially when I saw the AI repeatedly adjusting based on my rejection in order to figure out “what is real,” I became aware of which details truly mattered in my real memory and which ones I had never paid attention to myself.
Therefore, I feel that this workshop not only taught me a new prompting technique but also made me aware of the power AI has in shaping narrative and experience. At the same time, it reminded me to maintain agency over my personal experience. When we use AI-generated content, it may look like the machine is expressing our thoughts, but in reality, we are also re-interpreting ourselves through interacting with AI—and sometimes this reinterpretation is more important than the content itself.
Week 8 Digital Ecologies in Practice
This week's workshop focused on Digital Ecologies in Practice, and we visited Kirkgate Market in the center of Leeds. I had heard before that this market offers food from many different cultures, fresh fruits and seafood, as well as all kinds of daily products. It is one of the largest and most historic markets in Leeds, so I was really looking forward to going there.
After arriving, the tutor divided us into two groups, and I followed Holly to complete the task of recording smells. As we explored the market, my classmates and I tried different ways to document the smells around us. At first, we only thought of obvious methods such as taking pictures or videos of food and spices. But after Holly reminded us, we realized we could record the process that produces the smells, such as the sound and movement of chefs frying seafood or preparing dishes. In addition, we used text to describe what ingredients we could identify from the smell, and we also used audio to capture sizzling or cooking sounds. This made me realize that smell is not an isolated sense, when combined with sight and sound, it becomes a more layered sensory experience. In this sense, recording is not simply copying what we sense, but actually recreating and transforming it.
An hour later, I joined the second group. Kaajal introduced us to different types of mineral salts and showed several jars containing salt, pepper, cinnamon, garlic skin, coffee beans and other materials. After they ferment, they create bubbling sounds, and by wearing headphones, we could hear what was happening inside the jars. It was the first time I realized that digital technologies do not only reproduce sensory experience, but also allow us to perceive things that we normally cannot sense, for example, hearing the fermentation process. This installation essentially links food, time, materiality and our bodily senses to digital media, forming a new sensory ecology.
Through this workshop, I came to understand that digital ecologies are not simply about digital objects, but about the relationships between digital technologies, materials, senses, and human bodies. The market itself already connects the journey of food from land to table, and digital intervention makes this ecology more visible, while also allowing our bodies to participate more actively. I realized that when technology draws our attention to things we usually overlook, it also reshapes the way we understand the world.






Week 9 Creative Hacking, Senses and Bodies
This week we visited the HELIX workshop, and the moment I entered the space, I was amazed by the creative equipment available there: LEGO sets, sewing machines, 3D printers, a recording studio, and even laser cutters. It made me realise that HELIX is not only a technical facility, but also a place that encourages creativity and experimentation. The tutor also mentioned that students can book and use the space for personal projects, which made me feel excited about future possibilities.
After the short tour we returned to the classroom and our group received a handbook and a set of components. The most important part was the Arduino microcomputer, a small circuit board already soldered with many components. Under the tutor’s guidance, we connected the board to a laptop and used the Arduino software to programme it. At first we simply controlled the LED light to turn on and off in fixed intervals, and later we added sensors and resistors, eventually creating a simple temperature-sensing “Love-O-Meter.”
Although I had only learned a little bit of coding before, it felt fascinating to write something myself and immediately see a physical reaction from the device. Programming had always felt abstract to me, because it's hard for me to read those text and numbers, but now I could literally see how code becomes light, data, or movement. It made me understand for the first time the direct relationship between software and hardware.
During the process we also experienced some unexpected issues, such as incorrect wiring or sensors not responding. But our tutor kept reminding us that failure is part of hacking and experimentation. This helped me understand the meaning of “creative hacking”: it is not only about technical engineering, but also about exploring how digital systems sense and interact with the human body.
What I found especially inspiring is that technologies like sensors are already widely used in real life, for instance, electronic prosthetics allow people with disabilities to control artificial limbs through muscle signals, and smart health devices monitor body conditions such as heart rate or oxygen levels. These examples made me realise that sensing technology is not only about data, but also about extending human capability and improving accessibility.
Therefore, this Arduino experiment is more than just a small task, but it offers an entry point into thinking about digital bodies, sensing technologies and human identity. It also made me reflect on how digital ecologies shape the way humans relate to technology. Perhaps in the future, the boundary between bodies and digital systems will become even less clear, and this is exactly why we should learn to understand and critically reflect on these technologies now.




Week 10 Interactive Narratives
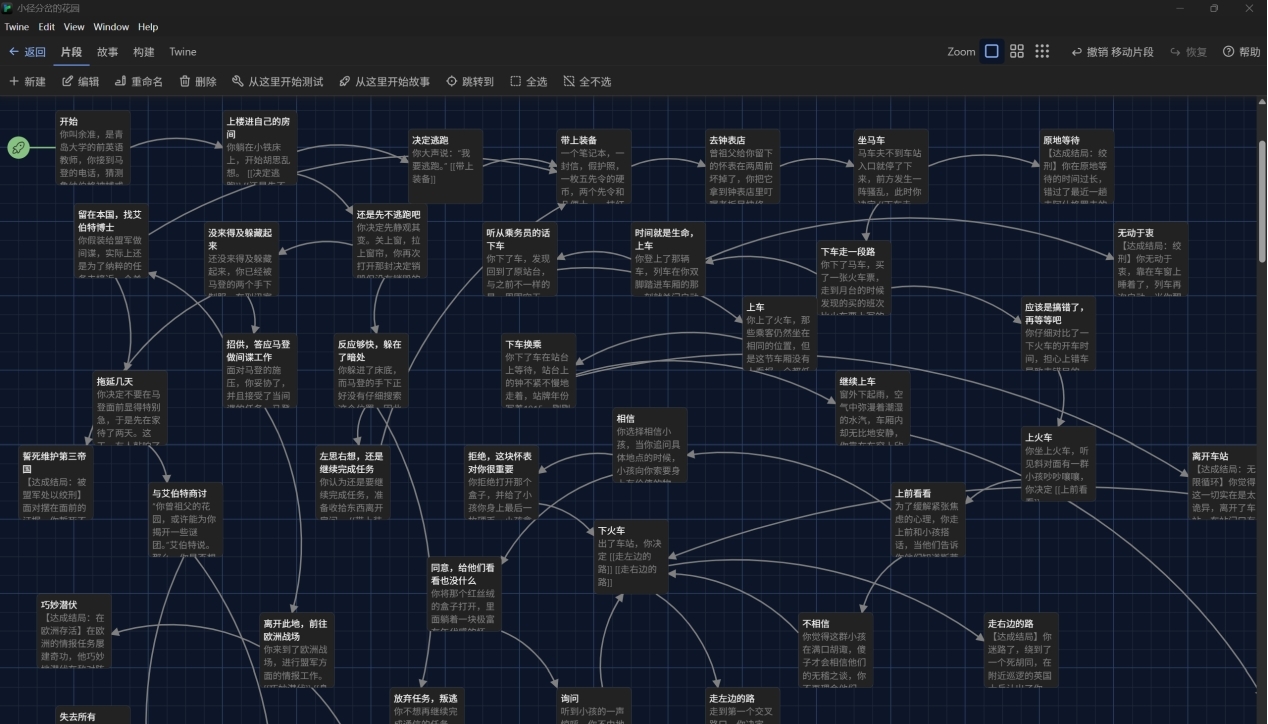
This week's workshop focused on Interactive Narratives, and we mainly learned how to use Twine to create interactive storytelling pieces. At the beginning of the session, we played a simple game called Spacefrog. Although the game was very short, we could help the frog prepare for its space trip, meet a sheep on a distant planet, and finally return to Earth to see its friend just by clicking options. Even with such a small scale, the character was successfully shaped and a complete narrative loop was created. I realized that interactive storytelling does not necessarily require complicated systems, once player choices influence the experience, the work already has interactive and narrative value.
Actually, I first encountered Twine during my undergraduate studies. At that time, we adapted The Garden of Forking Paths into an interactive story and were allowed to add new branches. That was the moment I realized that creating a compelling interactive story involves more than just branching, it requires maintaining logical consistency. Every branch needs not only to advance the plot but also connect to the central theme, and every choice should be meaningful. It is also necessary to design transitions and hints that guide readers to make decisions, so the story doesn't feel sudden or disconnected.
When I began to create my own Twine story, I realized that writing an interactive narrative is very different from writing a linear one. I had to think not only about what happens in the story, but also about how the reader moves through it. Every link became both a part of the plot and a decision point. This made me pay attention to structure in a new way. I could see how one small change could shift the entire flow of the story.
This week's workshop made me rediscover the potential of Twine. It reveals narrative structures visually and encourages creators to consider how choices make a difference. In contemporary narrative-driven games, this multi-branch structure has become very sophisticated. For example, the visual novel Raging Loop essentially uses a werewolf-style time-loop narrative and builds complex storytelling across multiple timelines, while its menu clearly shows the structure of both the main and side routes. This visual representation made me realise that interactive narrative is not just about telling a story, but about constructing a world that players can explore or even break open.
When coming back to Twine, although it is simple, it offers the logic of narrative itself. We can even treat Twine as a conceptual tool to understand the structure of a story, the consequences of choices, and the connections between narrative nodes. In today's digital narratives, whether in large-scale interactive games, visual novels, commercial media, or even social media content, interaction has become an essential part of storytelling.
Therefore, I think this weeks workshop is not only about learning a tool, but also about rethinking the nature of contemporary storytelling: narrative is no longer a single line, but a network that can extend, loop, and open up in many directions.